
December 19, 2025
Your LLM translation worked perfectly in your notebook. Then you shipped it to production.
German subtitles ran 240% longer than the source audio. Japanese merged two separate sentences into one. Timestamps drifted out of sync. Same prompt. Same model. 60% failure rate.
👋 Hi everyone! We’re Dave, Josh, and Anu. Welcome to AI in Production Field Notes. Each week, we share real-world lessons from teams deploying enterprise-grade AI systems in production. No fluff.
Every edition distills a single case study, unpacking the frameworks and system design decisions that actually matter once AI systems leave the demo stage.
This teaser highlights the core ideas behind Vimeo’s subtitle and dubbing pipeline, and why, at scale, the LLM call itself is only a small part of the problem.
If you enjoy the teaser below and would like to receive the full weekly deep-dive you can sign up here 👉 full edition
Why this breaks in production
After processing thousands of videos across 20+ languages, Vimeo discovered a hard truth:
The single LLM call is only ~5% of the work.
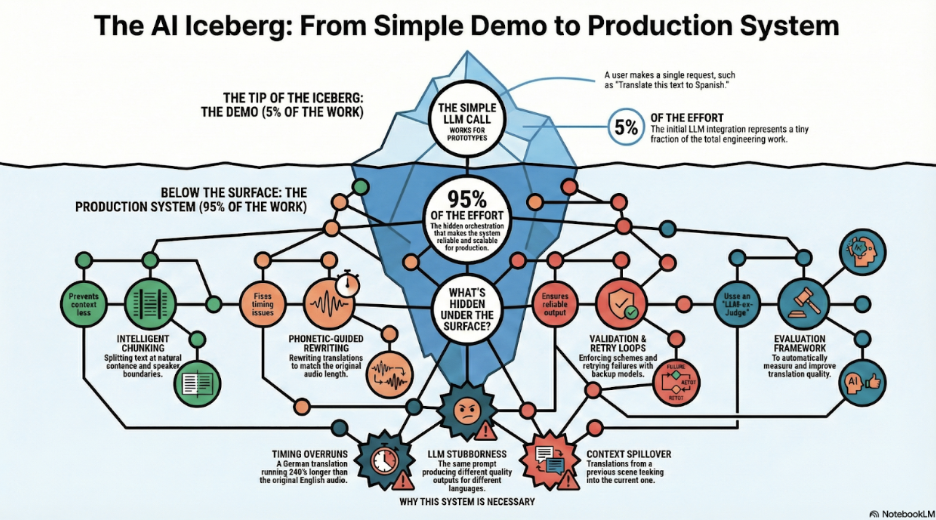
What’s hidden beneath the surface:
- Speaker-aware chunking (not token-based)
- Validation loops with retries
- Phoneme-guided rewrites to control timing
- Language-specific edge cases
- Evaluation systems to catch failures early
Without these layers, quality degrades fast, and trust follows.
What actually works
Instead of treating translation as a one-shot prompt, Vimeo built a layered, production-grade system designed to balance:
- Quality
- Timing
- Cost
- Scale
Numerical constraints beat vague instructions. Validation beats blind retries. Evaluation makes iteration possible.
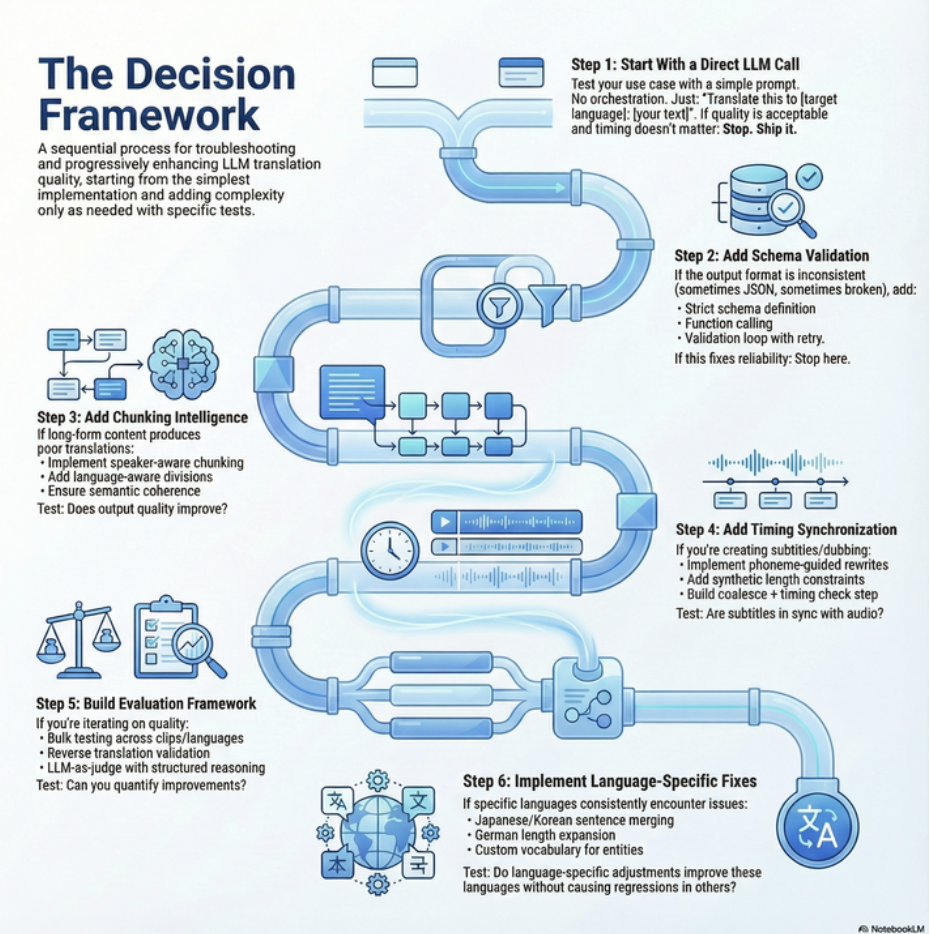
The complete write-up breaks down Vimeo’s full subtitle architecture, including chunking strategies, phonetic constraints, validation design, async orchestration, and LLM-as-judge evaluation.
We hope you enjoy!