
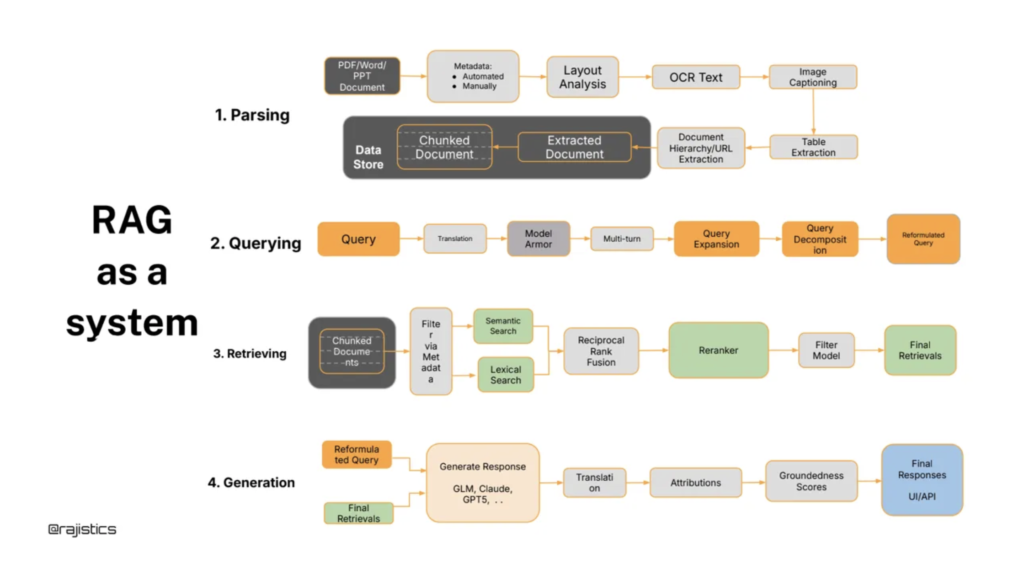
If you’ve shipped a RAG system beyond a proof-of-concept, you’ve probably run into the same pattern:
The demo looks strong.
Then production shows up, real users, real traffic, real permissions, real budgets, and the system starts answering confidently from the wrong context.
That usually isn’t a “model problem.”
It’s a retrieval problem.
This is a recurring production pattern across teams operating RAG in the wild: once you move from “it works” to “we can run it,” retrieval, not generation, becomes the dominant risk.
(These notes are synthesized from deployed systems and practitioners experience operating retrieval at scale, including lessons drawn from Rajiv Shah’s real-world work in production retrieval.)
Why demos hide the real failure modes
RAG demos typically include:
- a small or curated corpus
- friendly queries (or a handful of “golden” examples)
- low concurrency
- permissive access (or no access control at all)
Production introduces:
- drift (docs change, terminology evolves, corpuses grow)
- load (tail latency, caching behavior, retries, concurrency)
- constraints (latency SLOs and budget ceilings)
- access control (who can see what, and why)
And the user-facing symptom tends to be consistent:
trust erosion, because the system “sounds right” while being wrong.
The retrieval breakdowns that keep showing up in production
1) Relevance drift
Over time, retrieval quality can degrade quietly:
- new content crowds out canonical sources
- embeddings age poorly relative to changing query patterns
- chunking that was “fine” becomes a long-term liability
The worst part is that the system still retrieves something, so the failure often isn’t obvious until users complain.
2) Latency + cost blowups
Teams often try to “fix” quality by doing more retrieval work:
- larger top-k pulls
- reranking everywhere
- longer contexts “to be safe”
- retries under load
At real traffic levels, these choices compound quickly, and retrieval becomes the dominant driver of both tail latency and cost.
3) Weak or missing hybrid baselines
A common anti-pattern is jumping straight to vector search without proving baseline strength.
In many org corpuses, strong lexical + metadata filtering is hard to beat. If you can’t measure whether a hybrid improves your query distribution, you don’t have a retrieval strategy, you have a preference.
4) Permission mismatches
Hallucinations are embarrassing. Permission bugs are incidents.
Retrieval can fail “upstream” in ways that no prompt can patch:
- ACL metadata missing at ingest
- incomplete filtering at query time
- caching across permission boundaries
- staging environments that never reflected real access complexity
5) No retrieval observability
When answer quality drops, teams often can’t answer basic questions:
- What did we retrieve?
- What got filtered and why?
- What ranked #1 and what signal pushed it there?
- Did the model actually use the evidence?
Without retrieval-level logs and metrics, teams end up prompt-tuning a system whose core failure is upstream.
The framing that holds up: a “retrieval contract”
If you want RAG to behave in production, treat retrieval as its own system with its own contract:
Given this query and this user, can we fetch the right evidence within our latency + cost budget, while enforcing access control correctly?
That contract forces clarity on:
- what “right evidence” means (for your domain)
- the retrieval SLO (not just end-to-end latency)
- the cost ceiling per request
- permission guarantees (non-negotiable)
Two quick checks to run this week
Can you beat a strong baseline?
Pick 50–100 real queries from production (or logs) and compare:
- lexical baseline (keyword/BM25-style)
vs - your current retriever (and hybrid, if used)
If you’re not reliably outperforming the baseline, don’t scale complexity, fix fundamentals.
Can you explain a bad answer end-to-end?
For a known failure, can you inspect:
- retrieved items + scores + rank
- what got filtered (ACL/metadata) and why
- retrieval latency breakdown
- whether the answer actually grounded in retrieved evidence
If not, you don’t have a debugging loop yet, and quality will remain “mysterious.”
Intentional cutoff
This post stops here on purpose.
The full field note goes deeper on the production mechanics: what hybrid baselines actually look like in practice, the observability signals that matter, and the common “retrieval fixes” that backfire on latency/cost.