
TMLS Insights | Week of May 4, 2026
This is the first in a series of practitioner-focused posts by Graham Toppin
Graham is a Co-founder and Analyst at Peerlabs.ai, a subscriber-funded intelligence firm focused on primary research on emerging technology.
No news roundups. No vendor hype. We want to give you concrete advice you can test this week, grounded in what we’re hearing from practitioners and seeing in our own work.
Six months ago, a lot of us were asking: “should I run local models?” The question has shifted. It’s no longer about ideology or capability parity with frontier models. It’s about operational resilience, sovereign data, and control. What happens when your primary provider rate-limits you, changes its pricing, or goes down during a deadline. In one of my recent deep dives with a technical team, their lead said “Remember how ‘Github is down’ used to be the reason for no work getting done? Now it’s ‘Claude is down’.”
Folks talk about Claude 4.5 Opus as an inflection point. There has been a similar inflection point for Open Weight, Open Source models.
The pricing picture is fluid, but here’s the pricing reality as of May 4, 2026:
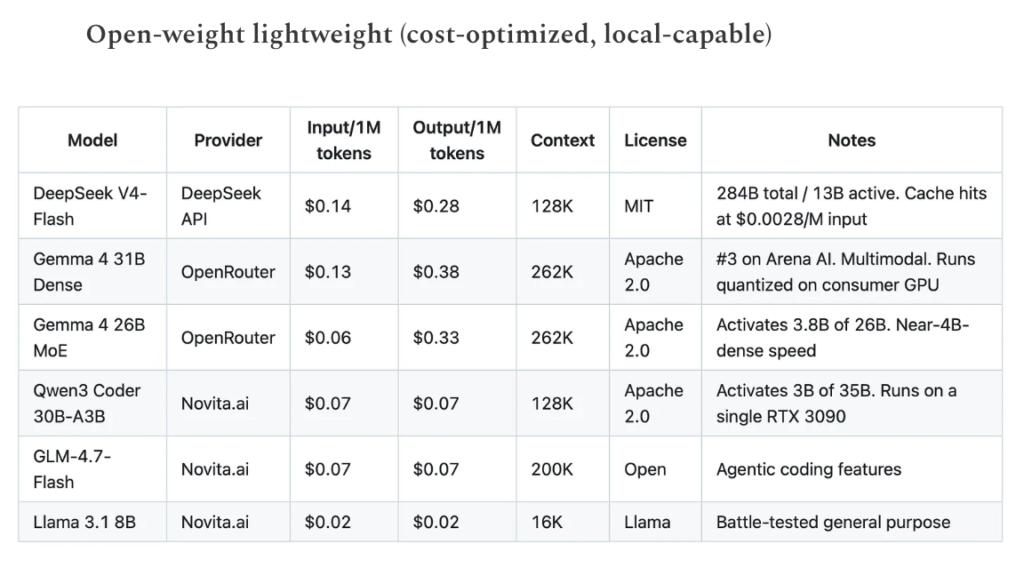
Frontier (proprietary):
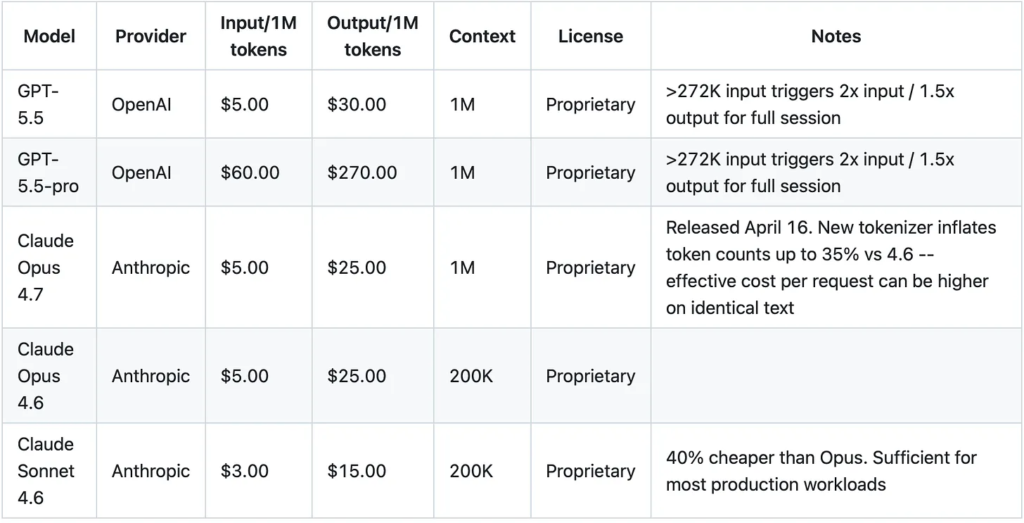
Open-weight heavyweight (frontier-competitive):
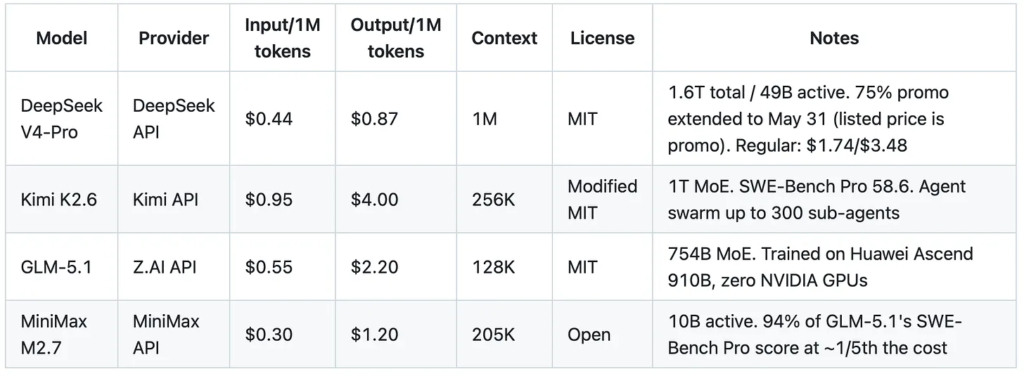
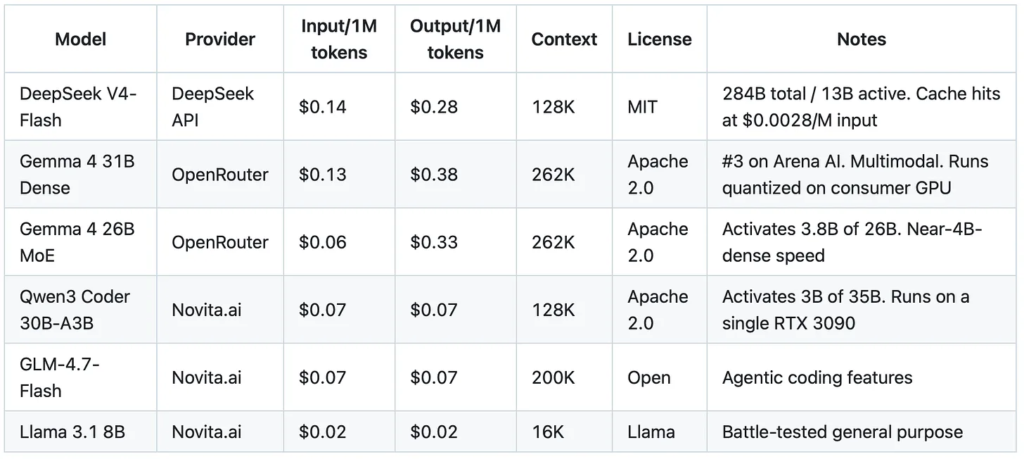
Open-weight lightweight (cost-optimized, local-capable):
(sourced from each provider’s publicly listed pricing pages and OpenRouter, verified May 4, 2026. DeepSeek V4-Pro promo surfaced in an earlier version of this article, was to expire May 5, but has been extended to May 31. Prices change frequently; this represents the latest as of this writing)
The spread tells the story. At the lightweight end, Qwen3 Coder at $0.07/$0.07 is 40x cheaper than Sonnet 4.6 on input and 214x on output. The heavyweight open-weight models sit in between: DeepSeek V4-Pro at $0.44/$0.87 (promo) delivers frontier-competitive reasoning at roughly 1/7th the cost of GPT-5.5. MiniMax M2.7 at $0.30/$1.20 scores 94% of GLM-5.1’s SWE-Bench Pro at a fraction of the cost. In March and April, I started paying closer attention to open-weight models after folks in my network told me they were saving 2-3 orders of magnitude relative to the frontier labs on specific workflows. We’re seeing similar results in our own pipeline at Peerlabs, where we use Novita.ai as a fallback during Anthropic rate throttling.
Caveat emptor:
- These savings are workload-dependent. A frontier model at $5/M may still be the right choice for complex reasoning or long-horizon agentic tasks.
- The heavyweight open-weight models (DeepSeek V4-Pro, Kimi K2.6, GLM-5.1) are closing the gap on frontier for coding and reasoning, but DeepSeek’s own technical paper acknowledges V4 lags GPT-5.4 and Gemini 3.1 Pro by roughly 3-6 months on some tasks.
- Open-weight models tend to shine on constrained, well-scoped tasks: classification, extraction, summarization, code generation in familiar domains, and first-pass drafting. The cost advantage is real; the capability trade-off is task-specific.
- Test on your workload, not on benchmarks.
A stack worth trying this week:
This is a recipe I’ve used with great success:
For coding and implementation — Novita.ai (hosted open-weight models, OpenAI-compatible API, no rate limits, pay-as-you-go) + one of:
- Qwen3 Coder 30B-A3B for coding tasks. Activates only 3B of 35B parameters per token. Runs on a single used RTX 3090 if you want to self-host. $0.07/M on Novita if you don’t.
- GLM-4.7-Flash for general-purpose work. 200K context, agentic coding features, $0.07/M on Novita.
- DeepSeek V4-Flash for reasoning-heavy tasks. Activates 13B of 284B parameters. $0.14/$0.28 on DeepSeek’s own API, also available on Novita.
For planning and reasoning — use the heavyweights via their native APIs:
- DeepSeek V4-Pro for deep reasoning. $0.44/$0.87 (promo until May 5). On Novita, it’s $1.74/$3.48. 1M context window.
- Kimi K2.6 for long-running agentic work. $0.95/$4.00. 256K context, agent swarm support.
- GLM-5.1 or MiniMax M2.7 for coding. GLM-5.1 at $0.55/$2.20; MiniMax M2.7 at $0.30/$1.20.
We tend to use bigger models for planning and reasoning. A winning combination for example, is using a frontier model, or one of the larger open weight models for partnering on planning, creating PROJECT.md, HANDOFF.md or your context du jour, and having cheaper agents implement the design.
Pair with an open harness:
- pi (https://github.com/badlogic/pi-mono/tree/main) – minimal, bootstrapped harness. I can’t say enough good stuff about pi (see Mario Zechner’s talk for more – you may fall in love with it too) Fair warning, it’s no bells included. You’re going to have to build your harness up from a minimal baseline. Not for everyone, but if complete control is your jam, this is the harness for you. More on this later. If you want to get started with Novita.ai + pi, this is my most recent models.json for Novita.
- opencode (https://github.com/anomalyco/opencode) – terminal-based coding agent, works with any OpenAI-compatible API endpoint. Point it at Novita, your local Ollama instance, or any provider. Swap models by changing one environment variable, or within the harness with Ctrl-P. Has explicit “Plan” and “Build” modes.
- aider (https://github.com/Aider-AI/aider) – mature, well-documented, works with local and hosted models.
The key insight from practitioners we’ve spoken with3: the harness (opencode, aider, Claude Code, Cursor) matters more than which specific open-weight model you pick, because harnesses differ in how they manage context, caching, and tool invocation. A good harness on a cheap model often outperforms a bare API call to a frontier model.
What we’re planning to test (and will report on): We are planning to run systematic comparisons across these stacks on our own production workloads over the coming weeks: same tasks, same evaluation criteria, measured cost and quality. We’ll publish the methodology and results. For now, the recommendation is anecdotal but consistent across multiple teams: try it on a non-critical workflow this week and measure what happens.
If you’re running open-weight models in production, or if you’ve built internal tooling around agent context management, we’d like to hear from you. We’re collecting practitioner accounts (attributed or anonymous, your choice) for a more systematic write-up.
Reach out at [email protected]
TMLS Insights is produced by the TMLS Steering Committee and Peerlabs. We produce practitioner-focused analysis for the Toronto Machine Learning Society and MLOps World communities. Aspects of our research pipeline use AI; all claims are human-reviewed and sourced.